
Il y a 4 ans, je vous présentais quelques outils permettant de mettre en place un site Web fort trafic. C’est l’heure de mettre à jour cette architecture PHP en version 2018 ! Il s’agit d’un article contenant quelques pistes sur les principaux composants logiciels à utiliser afin d’obtenir des performances optimales sur votre socle PHP.
Sans plus attendre, voici donc une architecture PHP autorisant la montée en charge, les hautes performances et la scalabilité horizontale. C’est à dire la capacité à ajouter des serveurs pour encaisser des pics d’utilisation.
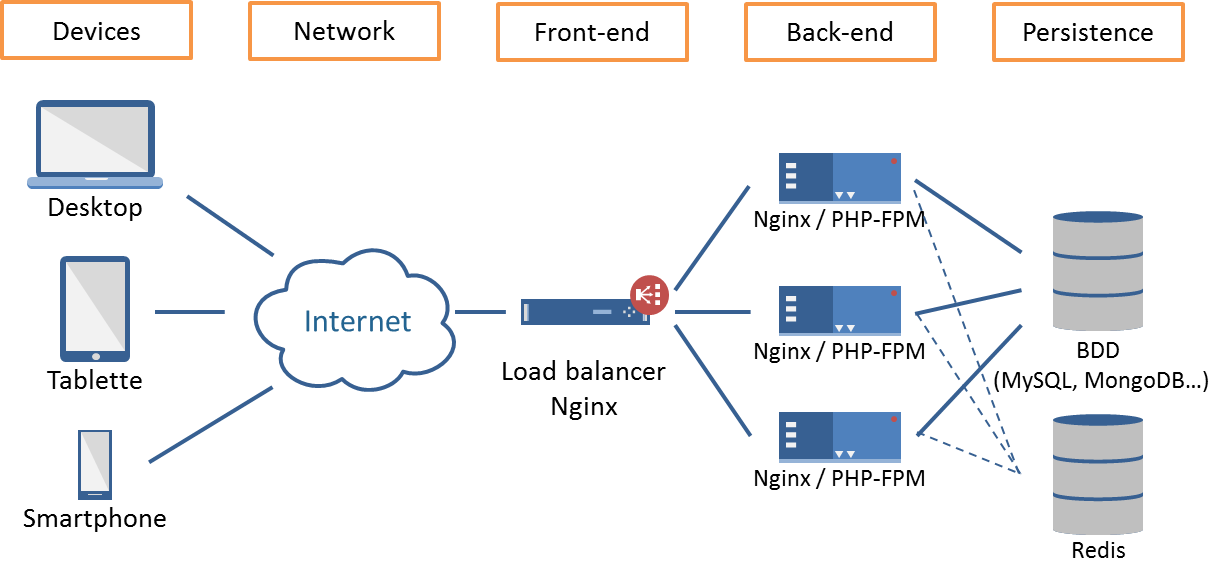
On remarque que le dispositif est articulé autour du composant Nginx qui joue le rôle de load balancer, de serveurs PHP-FPM et d’un composant Redis. Je vous détaille tout ça juste après.
Nginx pour le load balancing
Concrètement, le pivot de cette architecture haute performance est l’utilisation d’un load balancer (ou répartiteur de charge en bon français) comme point d’entrée : le front-end. L’idée est de pouvoir répartir la charge entre un ou plusieurs serveurs applicatifs qui traiterons la requête cliente : les back-ends. Le load balancer se charge de déterminer le bon back-end selon une stratégie qu’il est possible de configurer : poids donné au back-end, round robin, least-connections, ip-hash… Sur le schéma, vous voyez la présence d’un serveur Nginx. Rien ne vous empêche de le remplacer par un serveur HAProxy ou même par un serveur Apache… Nginx ou HAProxy, je vous laisse choisir : ici, là ou là.
Voyez comme il est simple d’utiliser le load-balancing sous Nginx :
http {
upstream myapp1 {
server srv1.example.com;
server srv2.example.com;
server srv3.example.com;
}
server {
listen 80;
location / {
proxy_pass http://myapp1;
}
}
}
Source : http://nginx.org/en/docs/http/load_balancing.html
Aller plus loin : https://www.digitalocean.com/community/tutorials/understanding-nginx-http-proxying-load-balancing-buffering-and-caching
PHP-FPM 7 pour le traitement des requêtes
PHP-FPM (pour PHP FastCGI Process Manager) a le très gros intérêt d’être complètement découplé du serveur HTTP qui l’utilise. Ainsi, peu importe que vous utilisiez Apache, Nginx ou HAProxy comme load balancer, le backend PHP-FPM est le même.
L’organisation d’un backend est la suivante :
- Nginx et PHP-FPM sont installés sur chaque backends ;
- PHP-FPM utilise plusieurs workers pour traiter simultanément des requêtes sur chaque backend ;
- L’application PHP est accessible par tous les workers via la configuration Nginx du backend ;
- Il est possible d’installer autant de backends que nécessaire pour gérer la charge de connexions.
Optez pour PHP 7 pour obtenir des performances optimales. PHP-FPM peut également tourner sur le même serveur que Nginx si vous n’avez pas besoin du load-balancing.
L’idée de cette architecture est de prendre en entrée une requête fournie par le serveur HTTP et de rendre une réponse qui sera renvoyée par ce dernier. Le load balancer ne s’occupe que de choisir le bon serveur applicatif. La vraie complexité est de gérer les sessions utilisateur qui, de base, sont gérées via le système de fichiers du serveur. Dans notre cas, c’est impossible puisque l’utilisateur peut être dirigé vers un serveur A pour sa première requête, vers un serveur B pour sa seconde, etc. C’est là que le prochain composant revêt toute son importance.
Exemple de configuration pour Symfony :
server {
server_name domain.tld www.domain.tld;
root /var/www/project/public;
location / {
# try to serve file directly, fallback to index.php
try_files $uri /index.php$is_args$args;
location ~ ^/index\.php(/|$) {
fastcgi_pass unix:/var/run/php7.1-fpm.sock;
fastcgi_split_path_info ^(.+\.php)(/.*)$;
include fastcgi_params;
# optionally set the value of the environment variables used in the application
# fastcgi_param APP_ENV prod;
# fastcgi_param APP_SECRET app-secret-id
# fastcgi_param DATABASE_URL "mysql://db_user:db_pass@host:3306/db_name";
# When you are using symlinks to link the document root to the
# current version of your application, you should pass the real
# application path instead of the path to the symlink to PHP
# FPM.
# Otherwise, PHP's OPcache may not properly detect changes to
# your PHP files (see https://github.com/zendtech/ZendOptimizerPlus/issues/126
# for more information).
fastcgi_param SCRIPT_FILENAME $realpath_root$fastcgi_script_name;
fastcgi_param DOCUMENT_ROOT $realpath_root;
# Prevents URIs that include the front controller. This will 404:
# http://domain.tld/index.php/some-path
# Remove the internal directive to allow URIs like this internal;
}
# return 404 for all other php files not matching the front controller
# this prevents access to other php files you don't want to be accessible.
location ~ \.php$ {
return 404;
}
error_log /var/log/nginx/project_error.log;
access_log /var/log/nginx/project_access.log;
}
Source : https://symfony.com/doc/current/setup/web_server_configuration.html
Redis pour gérer les sessions
Quand vous avez plusieurs backends en stratégie round-robin ou least-connections (les plus fréquents), un même client sera redirigé vers un serveur différent d’une requête à l’autre. Il n’est donc pas possible de créer une adhérence forte entre le serveur et le stockage des sessions (en système de fichiers par exemple). Dans ce cas, Redis est le composant parfait pour traiter le problème en fournissant un serveur de cache distribué qui permettra de centraliser l’ensemble de vos sessions, peu importe le serveur qui les créent ou les utilisent. Comme les sessions utilisateurs sont liées à un jeton placé sur chaque requête (par défaut c’est un cookie), peu importe le back-end qui recevra le jeton, il pourra retrouver les données des sessions sur le même serveur Redis. A noter que des solutions distribuées comme memcached fonctionnent également très bien !
Autre solution : si vous n’avez pas besoin de stocker des informations entre chaque requête, supprimez les sessions ! Vous pouvez sans problème gérer des requêtes stateless grâce à un jeton ajouté à celles-ci. Pour ça, je vous invite à aller faire quelques recherches sur les JSON Web Tokens (JWT pour les intimes).
MysQL, Maria DB, MongoDB…
Pour la partie stockage des données, mon avis est de moins en moins tranché. Les moteurs de base de données actuels sont performants et selon qui vous souhaitiez gérer vos données en relationnel ou en NoSQL, vous y trouverez votre compte. Sachez également que les hautes performances sur de gros volumes de données ne sont jamais magiques. Il existe des techniques qui permettent d’optimiser le traitement et la récupération des données :
- Indexes
- Dénormalisation
- Réplication
- Précaclcul de données
- Traitements asynchrones
- Moteur d’indexation type Elasticsearch
- etc.
Bref, selon votre applicatif et le volume de données à gérer, des solutions différentes seront possibles pour votre architecture. Notez bien que la mise en cluster sera probablement un prérequis au choix de votre SGBD.
Conclusion
Je vous ai présenté ici une architecture simple et rapide à mettre en oeuvre permettant de gérer un site Web fort trafic. Pour améliorer encore les performances et selon les fonctionnalités de l’application, il est possible d’ajouter des composants comme NodeJS ou RabbitMQ pour les traitements asynchrones. Typiquement, vous pouvez exécuter en asynchrone tous les traitements qui ne nécessitent pas un retour immédiat : envoi de mails, génération de fichiers, exports, etc. Ce principe basé sur une architecture distribuée fera l’objet d’un prochain article.
